Ein Problem der F-CPU könnte sein, das bereits der Prototyp
(implementiert au einem FPGA oder Asic ) mit den Mitbewerbern vergleichbar sein
muss.
Um sich behaupten zu können, muss also die maximale Performance aus der
bestehenden Technologie geholt werden. Es ist ja bekannt, das eine Pipeline
eine extreme Leistungssteigerung bewirken kann.
Die F-CPU ist superpipelined, damit ist eine theoretische Leistungssteigerung bei eben nicht änderbarer Laufzeit der Bauteile möglich.
speed = silicon technology x critical datapath length,
oder
speed = speed of one transistor x number of transistors
Beispiel für eine 4-Stufige Pipeline :
approximative cycles : 1
2 3 4
------------------------------------------------------------------------------
write imm to reg: write dest
load from memory: read address <access data: write dest
undetermined>
write to memory: read address <access data>
& data
logic operation: read operands, operation, write-result
arithmetic op.: read operands operation1 operation2 write result
move reg to reg: read source write dest.
Es ist ersichtlich, dass nicht alle Funktionen in Register schreiben, oder
aus ihnen lesen, bzw. Operationen auf Memory oder ALU ausführen.
Daher wird für die F-CPU eine Pipeline variabler Größe verwendet,
damit unterschiedlichste Prozesse gleichzeitig ausgeführt und beendet werden
können.
Das Problem des simultanen Zugriffs auf die Register, durch mehrere Prozesse
wurde durch zwei Busse gelöst, die älteste Instruktion hat dabei die
höchste Priorität.
Ein Prozessorkern diesen Typs hat die Eigenschaft, dass lange Operationen den
Prozessor nicht ausbremsen können.
Data Hazards werden durch diese Hardware noch nicht verhindert und die Lösung
in den Compiler ausgelagert.
Inkonsistenzen des Codes durch veraltete Registerinhalte sollen durch "Scoreboarding" vermieden werden, diese Technik ist relativ einfach:
Jedes Register bekommt ein Bit, das kennzeichnet, ob der Inhalt dieses Registers
sich in Bearbeitung befindet.
Dieser Vorgang ist transparent, wird vom Anwender nicht wahrgenommen und kann
nicht von aussen beeinflusst werden.
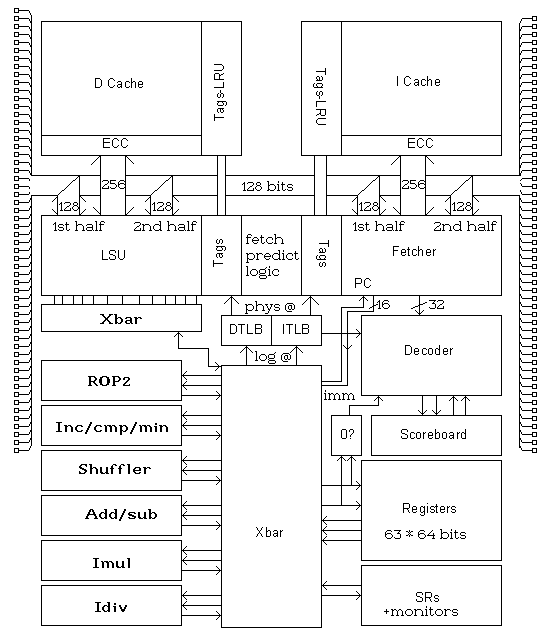
Um Laufzeiten durch unnötiges Passieren von nicht benötigten Pipeline-Stufen zu vermeiden, sind Register und Processing - Units durch eine "Crossbar" (Schaltmatrix oder "XBar") mit einander verbunden :
- dadurch ist es möglich Pipelinestufen zu übergehen
- ermöglicht "forwarding"
- reduziert die Anzahl an Registerports
Lese und Schreibzugriffe auf die Register erfolgt ausschliesslich über die Xbar.
Diese praktische Technik hat ihren Preis : ein Registerzugriff dauert zwei Takte, nach der Entschlüsselung der Registeradresse, einen Takt für die Registerbank und einen Takt zum passieren der Xbar.
Da es mehrere Funktional Units mit speziellen Funktionalitäten gibt, werden
sich Befehle vermutlich selten gegenseitig stören.
- ROP Unit für Boolsche Algebra (AND/OR/XOR etc.)
- Bit-scrambling Unit zum shiften, maskieren etc.
- Eine Increment Unit zum Rauf- und Runterzählen von Schleifenzählern,
adressieren von zusammenhängendem Speicher (z.B. Arrays) etc.
- ADD/SUB Unit (der Name sagt alles)
- Integer Multiply Unit
- Integer Divide Unit
- Load/Store Unit (nur diese Einheit hat Zugriff auf den Spicher)
- Weitere Einheiten um Floats zu unterstützen werden noch folgen